

DMTN-309
CM-Service Architecture#
Abstract
Overview of the role of the campaign management tool cm-service.
CM-Service#
The Campaign Management Team has been developing an orchestration tool called cm-service to support running large processing campaigns. This system is designed to automate as much of the team’s work as possible, enabling more efficient processing and a faster time to completion for campaigns.
Rubin Campaigns are organized as a “workflow of workflows”, where an overall data release production campaign is broken down into a series of sequential phases known as “steps”, and within each step a set of batch submissions are executed on subsets of the data until all data have completed that step. These individual batch submissions are also directed acyclic graph workflows (“quantum graphs”), but the dependencies inside that graph are managed by the execution framework and not campaign management’s tooling.
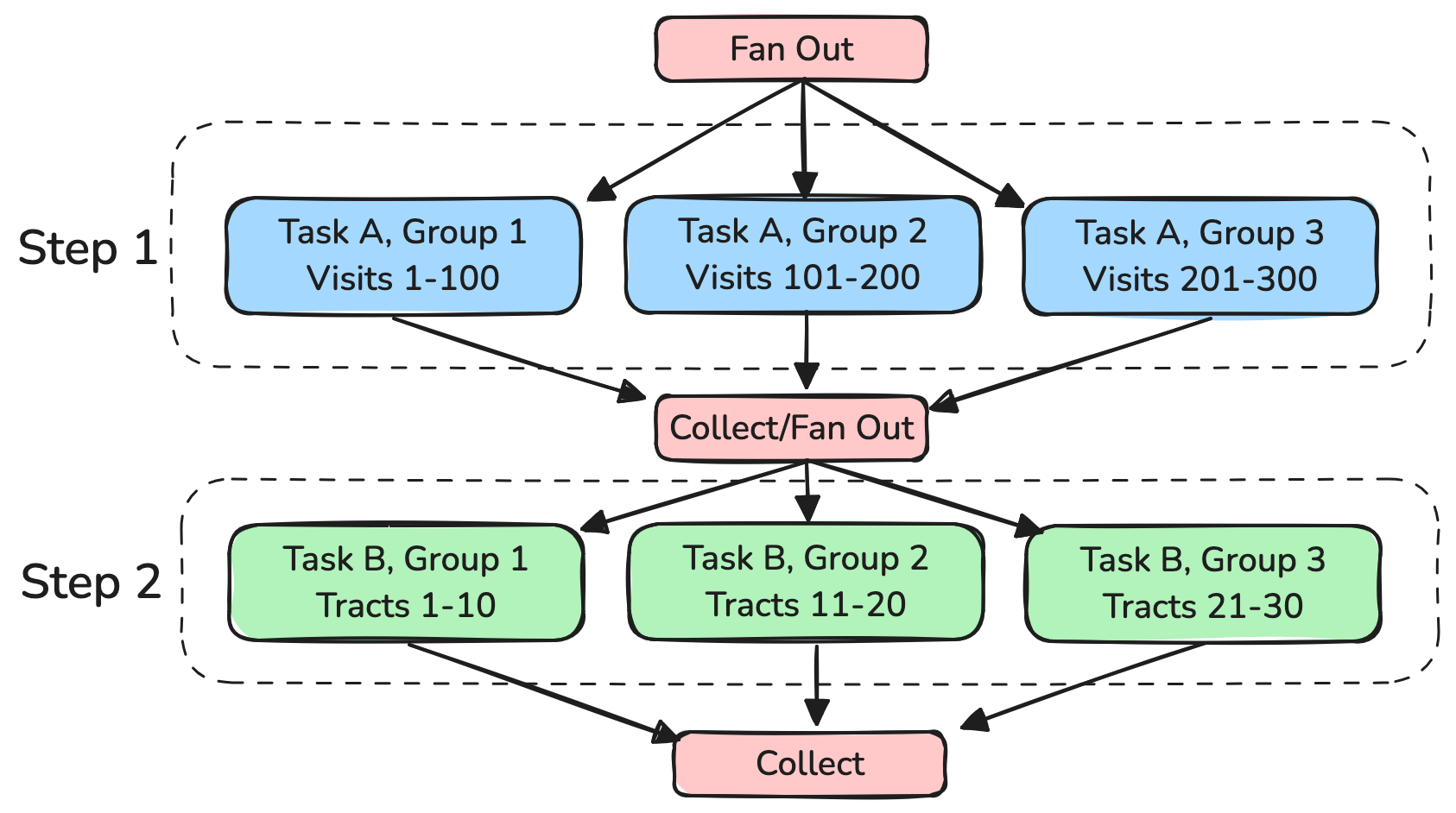
Fig. 1 Overview of the structure of a campaign in Rubin processing.#
Goals for CM-service#
Manage the submission of workflows to the batch systems, automatically submitting downstream steps after precursor steps have finished
Decompose large steps into a set of smaller batch submissions (“groups”), which can be submitted at a managed rate over many days or weeks.
For multi-site campaigns, coordinate which workflow submissions go to which sites, and trigger automatic batch submissions to those sites. Trigger data transfers as necessary.
Provide visibility into the status of the campaign processing, reporting which campaigns are in progress and the status of their steps and groups.
An implementation goal is to avoid cross-facility dependencies: each site will have downtime, but the other sites must be able to continue processing during that downtime.
Architecture#
The cm-service consists of four components:
An API service, which users can interact with via a command line interface to configure and manage campaigns
A back-end database to store campaign configuration and state
A web front-end, initially for monitoring campaign state but which could eventually support the same capabilities as the command line interface
A daemon service which effects the actual processing steps, based on information in the campaign database.
Campaign Configuration#
The CM-service database stores both the configuration and state of each campaign. This configuration system will be described in detail in a future DM tech note.
Interfaces to other services#
The user interaction with cm-service takes place via the API server or the Web UI, while interactions with data facility services are handled by the CM Daemon.
All of the processing that is triggered by cm-service is run via BPS. BPS provides an abstraction layer for submitting workflows to a variety of workflow management systems, and also provides a consistent interface for reporting the status of those workflows back to cm-service. BPS has plugins for submitting jobs via Panda, HTCondor, and Parsl, all of which are in active use.
Cm-service interacts directly with the butler for updating and modifying butler collections, and possibly for validation that input datasets are ready for processing.
Cm-service also interacts with rucio to define rucio datasets and add replication rules for data transfers after workflows have finished processing. It may also be necessary for cm-service to insert rucio rules for the transfer of input data for a workflow, either as part of a fan-out of (e.g.) global calibration products, or if the user chooses to reallocate where some processing is performed.
Example processing of a single workflow#
This sequence chart shows the interactions between the daemon and the various services it uses to process a single workflow and transfer the results.
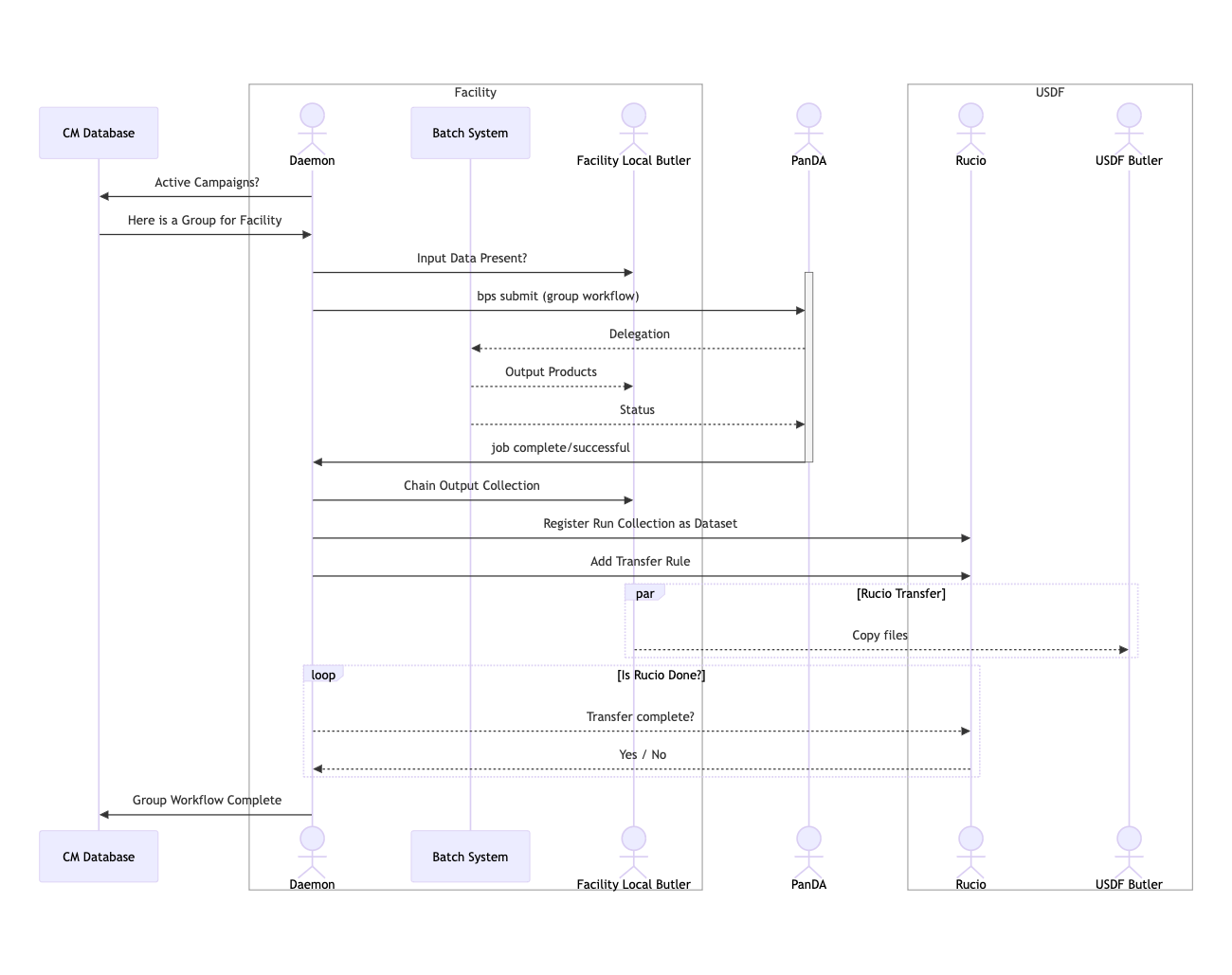
Fig. 2 Illustration of the interactions necessary for cm-service to process a workflow.#
Each of these actions have failure modes that cm-service needs to recover from; for example, the batch jobs may complete while the Rucio service is down, or butler collection management steps may fail if the butler registry is down. Cm-service is designed to track each of these necessary actions so that it can recover after services are restored, without needing to redo processing.
Open Questions#
While we have identified some of the pre- and post-batch-submission tasks which must be completed to support multi-site processing, as we begin to test more multi-site workflows it is likely that we will need to add or modify the work done between batch submissions.
Before beginning a processing step, it is critical that all of the input data are present as expected, including input images, calibration products, reference catalogs, and the butler collections that make all of these inputs accessible to the pipelines. Errors in these inputs can result in invalid output products, so it is critical to verify these before beginning. This may require additional interactions with Rucio or the butler at the start of a step.